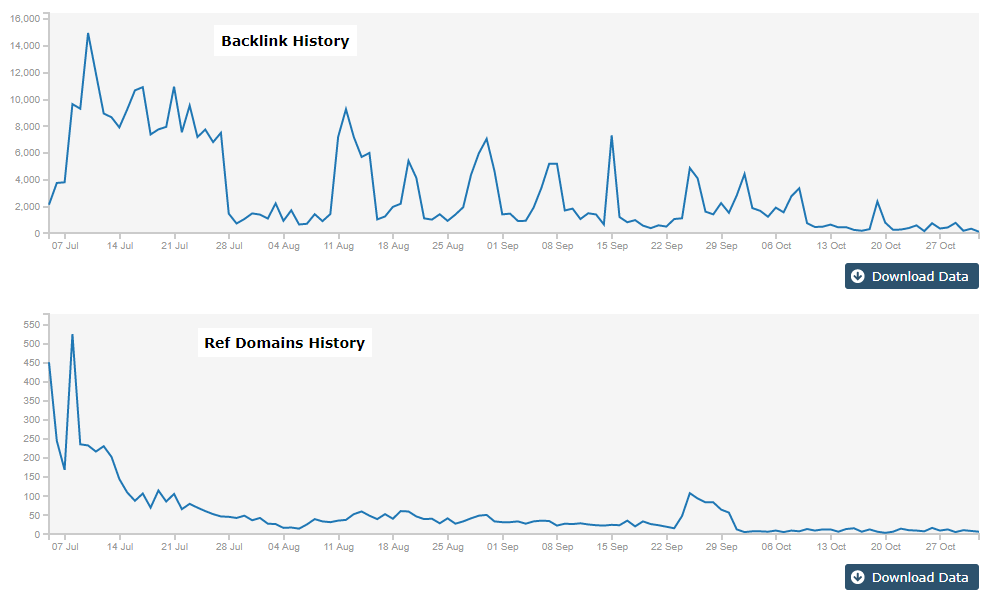
The web has a lot of web crawlers, some of them are good and vital for your website such as Google bot, others can be harmful like email harvesting crawlers and content scrapers. Link crawlers come short of harmful but far from useful. They are not useful for your website, and they are not harmful in way they try to scrape content or anything like that, but they could be consuming your server resources with no benefit.
For SEOs that adopt black hat tactics like PBN (private blog network) those crawlers are a nightmare and can expose the network to competitors if left open, which in most cases will lead to a spam report causing the whole network to be de-indexed + a manual action applied to the money site if not a total deindexation.
The most popular link crawlers are Majestic, Ahrefs, Moz and SEMRush, please note that their crawlers user-agents will not match their brand name and can change in the future, so it is very important to keep an up-to-date list with the user-agents used by those crawlers. I will list below different ways to block them:
Robots.txt:
You add few lines to your robots.txt file that can disallow most popular link crawlers:
User-agent: Rogerbot
User-agent: Exabot
User-agent: MJ12bot
User-agent: Dotbot
User-agent: Gigabot
User-agent: AhrefsBot
User-agent: SemrushBot
User-agent: SemrushBot-SA
Disallow: /
The method above will be very effective assuming:
- You trust those crawler to obey the directions in the robots.txt file.
- The crawlers do no keep changing their user-agent's names.
- The companies that operate those crawlers do not use third party crawling services that come under different user-agents.
.htaccess:
The issue with this method is that it requires your hosting provider to be Apache based, if your host supports htaccess you can use the code below to block most popular link crawlers:
<IfModule mod_rewrite.c>
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} (ahrefsbot|mj12bot|rogerbot|exabot|dotbot|gigabot|semrush) [NC]
RewriteRule .* - [F,L]
</IfModule>
This method is better that robots.txt as the crawlers have no choice but to obey assuming they are not changing their user-agents, or using third party crawlers.
Using PHP:
If you website is built with PHP like WordPress you can add the code below to your header.php to block all link crawlers:
$badAgents = array('rogerbot','mj12bot', 'ahrefsbot', 'semrush', 'dotbot', 'gigabot', 'archive.org_bot');
foreach ($badAgents as $blacklist) {
if (preg_match("/$blacklist/", strtolower($_SERVER['HTTP_USER_AGENT'])) ) {
exit();
} }
This methods is good if your server doesn't support .htaccess , if you are using this method you need to make sure you block also the RSS feed feature in WordPress, you can do that by adding the code below to your function.php file in the theme folder:
function wpb_disable_feed() {
wp_die( __('No feed available,please visit our <a href="'. get_bloginfo('url') .'">homepage</a>!') );
}
add_action('do_feed_xml', 'wpb_disable_feed', 1);
add_action('do_feed', 'wpb_disable_feed', 1);
add_action('do_feed_rdf', 'wpb_disable_feed', 1);
add_action('do_feed_rss', 'wpb_disable_feed', 1);
add_action('do_feed_rss2', 'wpb_disable_feed', 1);
add_action('do_feed_atom', 'wpb_disable_feed', 1);
add_action('do_feed_rss2_comments', 'wpb_disable_feed', 1);
add_action('do_feed_atom_comments', 'wpb_disable_feed', 1);
Aggressive blocking (for PBN users):
If you are a regular webmaster that it is willing to save some server resources by blocking link crawlers, applying any of the methods above should be suffice; however, if you are a webmaster that wants to leave no chance for those crawlers to sneak in, you need to apply harsher measurements.
Robots.txt will be as below:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
This will allow only Google bot to crawl the website assuming the crawlers will obey robots.txt directions. You can also allow other agents used by major search engines like Bing.
If you are using Wodrepss you can hide the links from all user-agents excluding Google using the code below in functions.php:
add_filter( 'the_content', 'link_remove_filter' );
function link_remove_filter( $content ) {
if (!preg_match("/google/", strtolower($_SERVER['HTTP_USER_AGENT'])) && !preg_match('/\.googlebot|google\.com$/i', gethostbyaddr($_SERVER['REMOTE_ADDR'])) ) {
$content = preg_replace('#<a.*?>(.*?)</a>#is', '\1', $content);
}
return $content;
}
This code will allow only Google to see the links, it verifies also that the IP address belongs to Google and it is not faked.
Make sure also to block RSS using the code listed in the previous step, the code above will not be impacted by those crawlers changing their agents or coming with different agent's names.